
 |
| Photo by Lautaro Andreani on Unsplash |
1. Folder Structure
Component-centric
file structure should be used which implies that all the files related to a
different component (like test, CSS, JavaScript, assets, etc.) should be kept
under a single folder.
For ex:
Components
|
--Login
|
--tests--
--Login.test.js
--Login.jsx
--Login.scss
--LoginAPI.js
2. HOC
It’s an advanced
technique in React which allows reusing component logic inside the render
method. An advanced level of the component can be used to transform a component
into a higher order of the component. For example, we might need to show some
components when the user is logged in. To check this, you need to add the same
code with each component. Here comes the use of the Higher-Order Component
where the logic to check the user is logged in and keep your code under one app
component. While the other components are wrapped inside this.
3. Decompose Big Component
Try to decompose large components into small components such that component performs one function as much as possible. It becomes easier to manage, test, reuse and create a new small components.
4. Use Functional or Class
Components based on Requirement
If you need to
show User Interface without performing any logic or state change, use
functional components in place of class components as functional components are
more efficient in this case.
Try to minimize logic in React lifecycle methods like:
componentDidMount();
componentDidUpdate();
These cannot be used with functional
components, but can be used with Class components.
While using
functional components, you lose control over the render process. It means with
a small change in component, the functional component always re-renders.
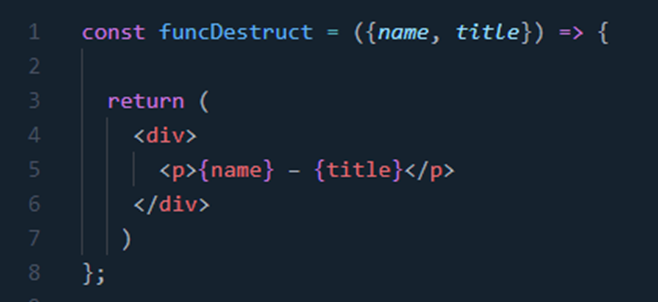
5. Naming and Destructuring
Props
Use meaningful
and short names for props of the component. Also, use props destructuring
feature of function which discards the need to write props with each property
name and can be used as it is.
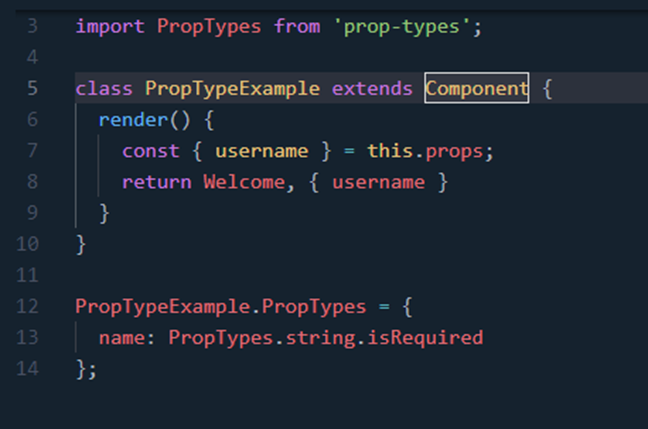
6. Use propTypes for Type
Check
It is a good
practice to do type checking for props passed to a component which can help in
preventing bugs. Please refer below code for how to use
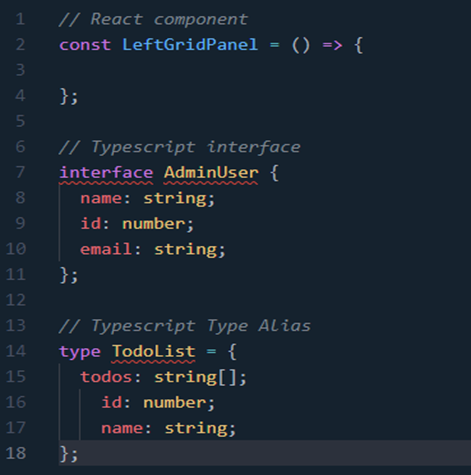
7. Naming Conventions
Use PascalCase in components, interfaces, or type aliases.
8. Avoid Unnecessary DIV tags
BAD:

GOOD:

9. Remove Unnecessary
Comments
Add comments
only where it’s required so that you do not get confused while changing code at
a later time.
Also don’t
forget to remove statements like Console.log, debugger, unused commented code.
10.The Rule of Max 3 props
inline
When there are
three or fewer properties, then you should keep those properties in their line
inside both the component and the render function.
Less than 3
props:
More than 3
props:

11.Use shorthand for Boolean
props
BAD:<RegistrationForm hasPadding={true} withError={true} />
GOOD:<RegistrationForm hasPadding withError />
12.Avoid curly braces for
string props
BAD:<Paragraph variant={"h5"} heading={"A
new book"} />
GOOD:<Paragraph variant="h5" heading="A new book" />
13.Write a fragment when a
DIV is not needed

14.Integrate self-closing
tags when no children are needed
BAD: <NavigationBar></NavigationBar>
GOOD: <NavigationBar />
15.Apply ES6 Spread Function
Using ES6
methods to send an object attribute would be a more straightforward and
effective method. All of the object’s props will be automatically inserted if
the phrase “…props” is used between the open and close tags.

16.Using Map Function for
Dynamic Rendering
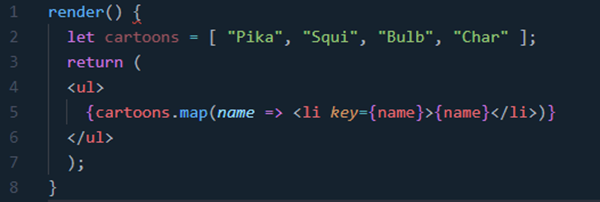
17.Use ES6 Spread Operator

18.Use Ternary Operators
BAD:

GOOD:
19.Use Object Literals
BAD:

GOOD:

20.Don't Define a Function
Inside Render
BAD:

GOOD:

21.Use Memo
BAD:
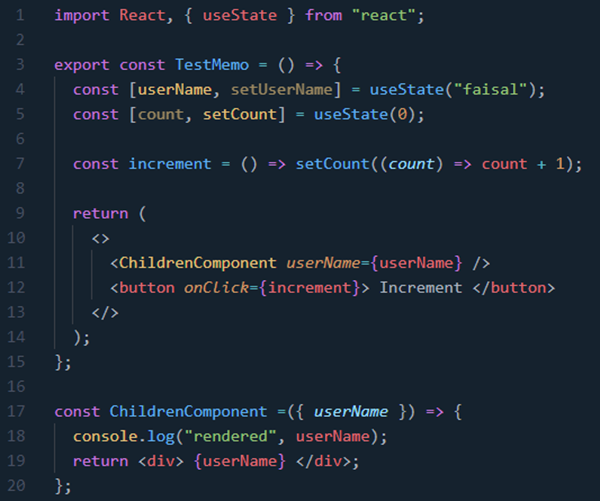
Although the child component should render only once because the value of count has nothing to do with the ChildComponent . But, it renders each time you click on the button.
GOOD:

Now, no matter how many times you click on the button, it will render only when necessary.
22.CSS in JavaScript
BAD:

GOOD:

23.Use Object Destructuring
BAD:

GOOD:

24.Avoid using string concatenation.
BAD: const userDetails = user.name + "'s profession is" + user.proffession
GOOD: const userDetails = `${user.name}'s profession is ${user.proffession}`
25.Import in Order
BAD:

GOOD:
The rule of thumb is to keep the import order like this:
- Built-in
- External
- Internal

26.Use Implicit return
BAD:

GOOD:
27.Quotes
BAD:

GOOD:
Use double quotes for JSX attributes and single quotes for all other JS.



